
A traditional automated test that fails does not know why it failed. It throws an exception, reports red, and stops the same outcome whether a real bug shattered the checkout flow or a designer renamed one CSS class. Loop engineering is the discipline, borrowed from how AI coding agents are built, of designing testing systems that actually investigate: act, observe what happened, reason about whether it matters, and adjust. This guide explains where the concept comes from, what it looks like applied to QA specifically, and why it is the architectural idea underneath self-healing tests, AI test generation, and the next generation of CI/CD quality gates.
By Robonito Engineering Team · Updated June 2026 · 18 min read
Quick stats
| Fact | Source |
|---|---|
| 60-70% of QA automation effort goes to test maintenance rather than new coverage | Capgemini World Quality Report 2025 |
| 40%+ of code shipped in 2025 was AI-generated, requiring AI-paced verification | Tricentis Transform 2025 keynote |
| 60% of AI-generated code contains issues requiring human or automated intervention | Tricentis QA Trends 2026 |
| Closed-loop CI/CD pipelines reduce regression detection time from 24-48 hours to under 2 hours | DORA State of DevOps 2025 |
| AI risk-based test orchestration can reduce overall test time by up to 40% while improving outcomes | Tricentis QA Trends 2026 |
Where "loop engineering" comes from
Loop engineering is a term that emerged from the AI coding agent world in late 2025 and early 2026, describing how tools like Claude Code, Cursor, and custom agentic pipelines are architected. The core definition, as the discipline is described across early technical writing on the subject, is the practice of designing AI-assisted systems around repeated cycles of action and feedback, rather than single-shot prompting or fixed linear chains.
The canonical loop looks like this:
Plan → break the goal into concrete steps
Search → find the relevant files, context, or state
Act → make the smallest coherent change or take the next action
Verify → run tests, checks, or observations against the result
Repair → use what verification revealed to correct course
Repeat → continue until a clear termination condition is met
The insight that makes this more than a diagram: a test failure, a type error, or a code review comment is not just an error message it is new context that should change what the system does next. A system that ignores this and simply repeats the same action regardless of outcome is not really automating anything. It is just running a script faster.
The distinction that matters most: open-loop vs closed-loop.
Open-loop system:
Executes a command without checking whether the result matches the goal.
Example: a deploy script that pushes code and exits, regardless of outcome.
Closed-loop system:
Observes the output, compares it against the goal, and adjusts.
Example: a CI pipeline that runs tests, reads the failure, and blocks
deployment until the regression is understood and resolved.
This idea is not new it comes directly from control theory, where a controller measures system output, compares it with a reference value, computes the error, and adjusts the input accordingly. What is new is applying this formal feedback-loop thinking deliberately to AI-assisted software systems including, directly and significantly, QA testing.
Why QA testing is the original closed loop and why most automation broke it
Here is the part that gets missed in most discussions of loop engineering: QA testing was already supposed to be a closed loop. The entire premise of the test-fail-fix-retest cycle is feedback-driven system design. You change code, run the test suite, read the failure, fix the issue, and run it again. That is a loop. A good one, when it works.
The problem is that most automated testing in production today is open-loop in disguise. A traditional Selenium or early-generation Playwright test does this:
1. Locate element by CSS selector
2. If found: interact with it
3. If not found: throw exception, report FAIL
4. Stop. No further investigation.
This is open-loop because step 3 contains zero reasoning. The system does not ask "did the application actually break, or did something irrelevant change?" It cannot distinguish a real regression from a renamed CSS class. The human has to close the loop manually investigate the failure, determine the cause, decide whether to fix the test or escalate the bug. That manual loop-closing is exactly the 60-70% of automation effort that the Capgemini World Quality Report 2025 attributes to test maintenance rather than new coverage.
This is the precise gap that AI-driven QA testing closes.
See loop engineering principles applied to modern QA testing
Robonito combines AI-powered test execution with confidence-based decision making, helping teams reduce repetitive maintenance through self-healing workflows, intelligent test generation, and automated evidence collection across web, mobile, API, and desktop applications.
The QA testing loop, mapped explicitly
Applying the act-observe-reason-adjust pattern directly to test execution produces a structure that explains what modern AI testing platforms are actually doing differently from their predecessors.
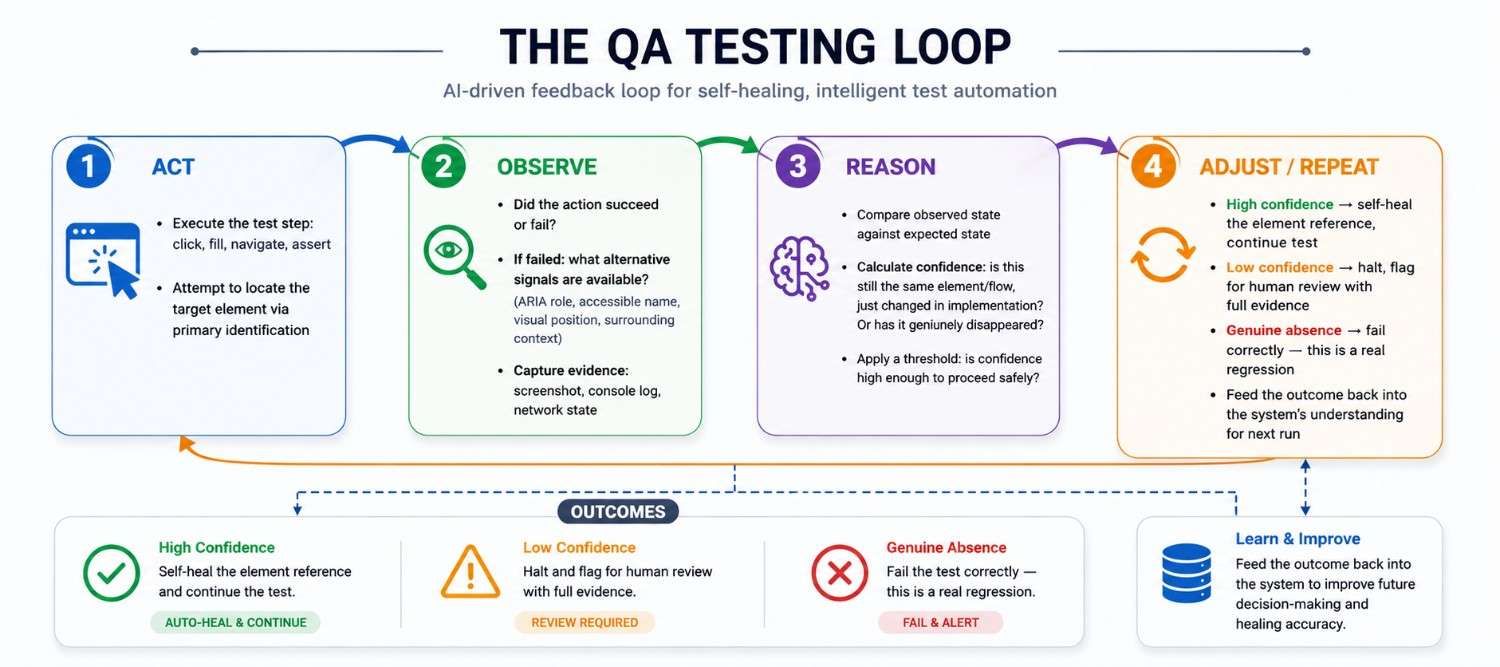
The critical design decision is in the REASON step. A system that always retries (no reasoning) is not closing the loop — it is just thrashing. A system that always halts on any failure (no adjustment) has a loop but never closes it productively. The discipline of loop engineering, applied to testing, is getting the REASON and ADJUST steps right: confident enough to act autonomously on the cases that genuinely do not need a human, conservative enough to escalate the cases that do.
Self-healing test automation: loop engineering's clearest application in QA

If you want to see loop engineering principles already operating in production QA tooling, self-healing test automation is the example. It is, in architectural terms, a closed feedback loop applied specifically to element identification.
// ─── Open-loop test (no feedback mechanism) ─────────────────────────
// This is what most automated tests still look like in 2026
await page.locator('.checkout-btn-primary-v2').click();
// If this selector is invalid: NoSuchElementException
// No investigation. No reasoning. No adjustment. Loop never closes.
// A human must manually investigate, identify the new selector,
// update the script, and re-run — closing the loop by hand.
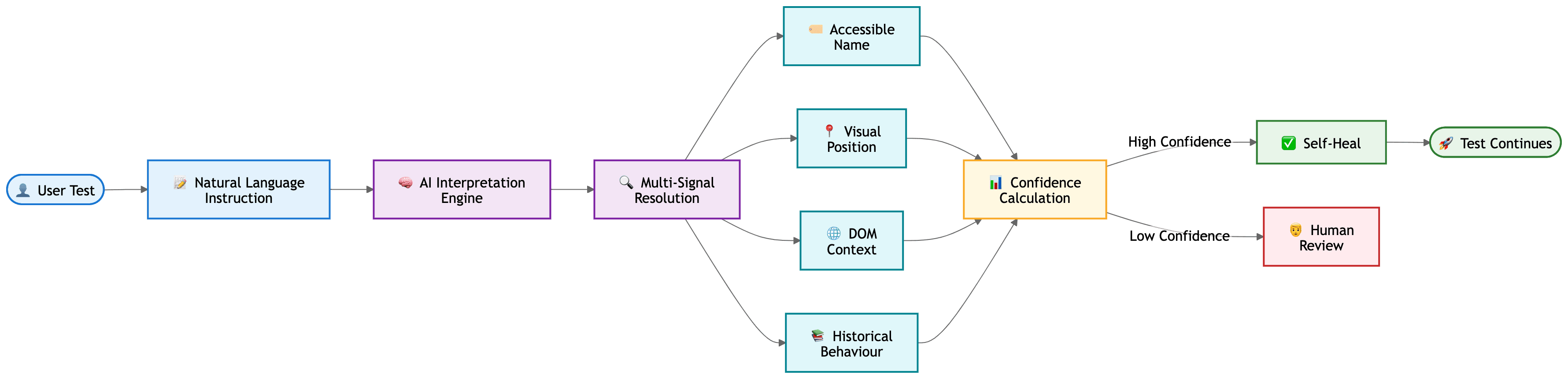
// ─── Closed-loop test (Robonito intent-based self-healing) ──────────
// Test step defined by intent: "Click the primary checkout button"
// ACT: attempt primary identification
// OBSERVE: primary locator fails — but gather alternative signals:
const signals = {
ariaRole: "button", // confidence: 1.00
accessibleName: "Place Order", // confidence: 0.97
visualPosition: "bottom-of-form", // confidence: 0.91
surroundingCtx: "after-payment-section", // confidence: 0.89
};
// REASON: combine signals into a confidence score
const combinedConfidence = 0.93; // above 0.85 threshold
// ADJUST: confidence is high enough — heal and continue
if (combinedConfidence >= 0.85) {
// Update element reference for this and future runs
// Log exactly what changed, for human audit
// Continue test execution without interruption
} else {
// Confidence too low — halt, flag for review with full evidence
// This is the loop correctly choosing NOT to act autonomously
}
The reason this matters architecturally, not just practically: the system is reasoning about its own observation before deciding what to do. That is the defining feature of a closed loop, and it is the precise capability that distinguishes self-healing automation from earlier "smart wait" or "retry on failure" approaches, which retry the same action blindly without reasoning about why it failed.
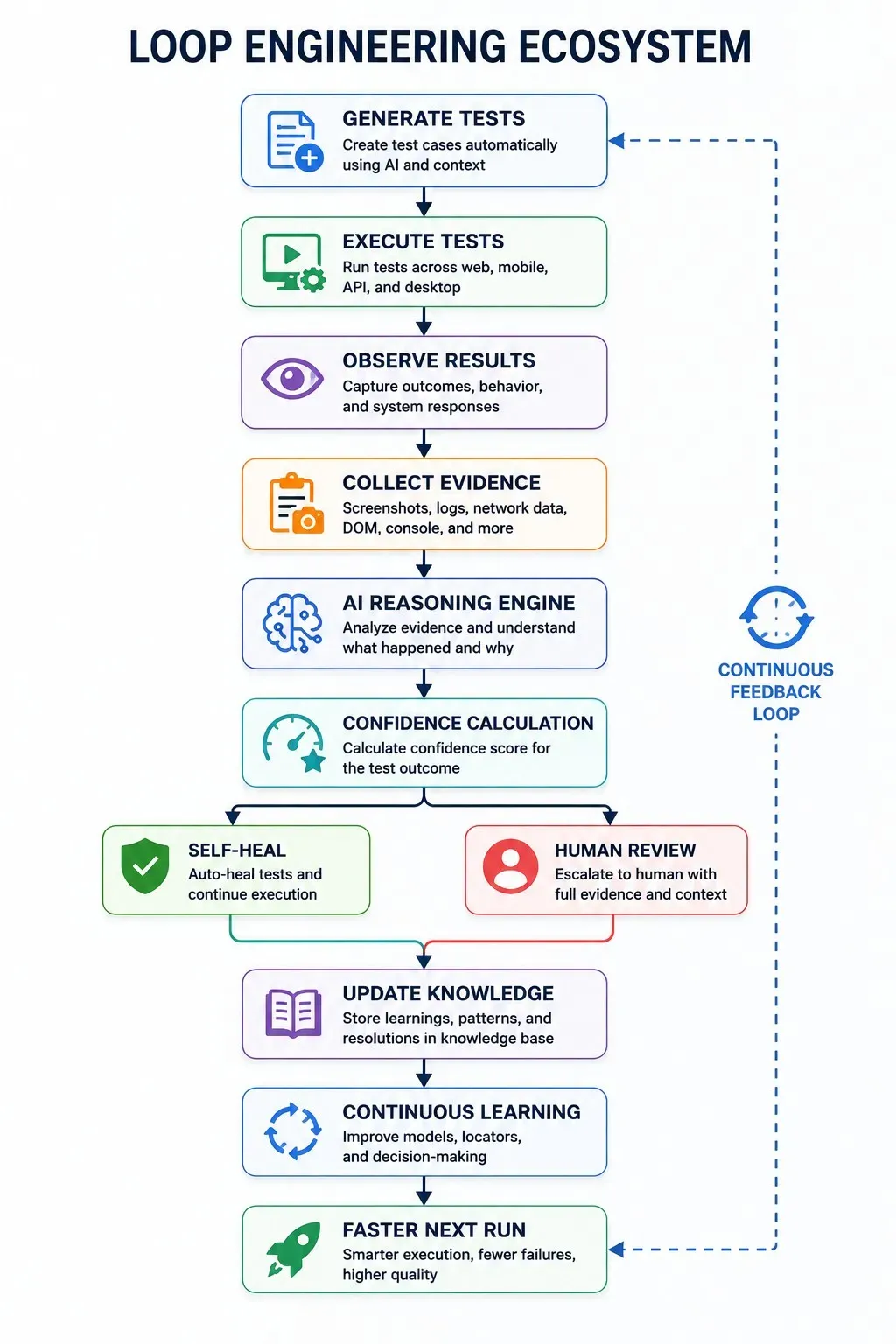
Beyond Self-Healing: Other Applications of Loop Engineering in QA
Self-healing is the clearest example, but the loop pattern appears throughout modern AI-driven testing, once you know to look for it.
AI test generation as a loop, not a one-shot
Open-loop test generation (early "record and playback" tools):
Record a user flow once → generate a fixed script → done.
No mechanism to verify the generated test is actually good,
no mechanism to expand coverage based on what was learned.
Closed-loop test generation:
ACT: Record a user flow
OBSERVE: AI analyses the flow — what assertions are testable?
What error paths are implied but not recorded?
REASON: Generate happy-path test + plausible error variations
(declined card, invalid input, boundary values)
ADJUST: Present generated tests for human review/approval
Incorporate reviewer feedback into future generation
This is why AI test generation in mature platforms produces more than a single recorded script — it produces a happy path test plus several boundary and error-path variations from one recording. The loop is reasoning about what additional test cases the recorded flow implies, not just replaying what was literally clicked.
Risk-based test prioritisation as a loop
ACT: Code change is pushed; CI pipeline triggers
OBSERVE: Which files changed? What is the historical failure
rate of tests covering those files?
REASON: Calculate a risk score per test — recently changed code,
historically unstable areas, revenue-critical paths
ADJUST: Run highest-risk tests first; if early high-risk tests
fail, the loop can halt the rest of the run early
rather than waiting for the full suite
This is precisely the "maximizing risk coverage" approach Tricentis describes as the emerging QA trend for 2026 — testing everything is not the goal; closing the loop on what matters most, fastest, is.
CI/CD itself as the outermost loop
ACT: Developer pushes code
OBSERVE: Pipeline runs unit → integration → E2E → security → performance
REASON: Each gate evaluates: does this result indicate a real problem?
ADJUST: Pass → proceed to next gate or deploy
Fail → block, notify, and (in mature pipelines) suggest
why — was this a flaky test, a real regression,
or an environment issue?
A CI/CD pipeline that runs the same flaky tests sprint after sprint without anyone investigating why they are flaky is, in loop-engineering terms, a loop that never closes. The system keeps observing the same failure without ever reasoning about its cause or adjusting its behaviour. This is exactly the failure mode the World Quality Report and DORA research both describe when they discuss test suites that erode developer trust over time.
Why this matters more in 2026 than it did in 2023
The discipline of loop engineering has become urgent specifically because of how much code is now AI-generated. Tricentis' CEO noted at their October 2025 Transform conference that over 40% of code written in the prior year was AI-generated and industry data suggests at least 60% of AI-generated code contains issues requiring intervention before it is production-ready.
This changes the QA equation fundamentally. When a human writes code, QA closes a loop around a relatively slow, deliberate process. When an AI agent generates code at high velocity, QA needs to close that same loop at AI speed which is impossible with open-loop testing that requires a human to manually investigate every failure before the loop can close.
2023 testing cadence:
Human writes code (hours/days) → tests run → human investigates
failures (manual loop closing, hours) → fix → retest
2026 testing cadence required:
AI generates code (minutes) → tests must run AND close their own
loop on routine failures (self-healing, automated) → only genuine
regressions escalate to humans → fix → retest (minutes, not hours)
This is the structural reason self-healing, AI-generated tests, and risk-based orchestration have moved from "nice to have" to "load-bearing" in QA strategy. The volume and velocity of change has outpaced what open-loop, manually-closed testing can keep up with. QA is becoming, in the words used at Tricentis' 2025 conference, the accountability layer for AI-driven software delivery and accountability layers cannot be open loops.
Traditional QA vs Loop Engineering
| Traditional Automation | Loop Engineering |
|---|---|
| Executes predefined steps | Observes outcomes continuously |
| Static locator logic | Context-aware reasoning |
| Pass/Fail decisions | Confidence-based decisions |
| Human fixes failures | AI resolves routine failures |
| Maintenance-heavy | Feedback-driven improvement |
Designing a closed-loop QA strategy — practical principles
If you are evaluating your own testing strategy through a loop-engineering lens, four design principles separate well-engineered loops from ones that thrash or stall.
1. Every failure needs an observation step, not just a report
Open-loop failure handling:
Test fails → log "FAILED" → move to next test
(No investigation. The same root cause repeats every sprint.)
Closed-loop failure handling:
Test fails → capture screenshot, console log, network state,
element fingerprint → classify: UI change, timing issue,
genuine bug, or environment issue → route accordingly
2. Define explicit confidence thresholds not binary pass/fail logic
A loop that only knows "succeeded" or "failed" cannot make nuanced decisions. A loop with a confidence score (0.93, 0.71, 0.42) can decide: auto-proceed above 0.85, flag for review between 0.60-0.85, fail outright below 0.60. This is the difference between a system that can act autonomously on routine cases and one that requires human judgment for every single event.
3. Give the loop a clear termination condition
Without stopping rules, automated systems either run forever or stop arbitrarily, a lesson from agentic coding that applies directly to test orchestration. A regression suite needs explicit completion criteria: all P0 tests passed, or a critical failure halted further execution, or a time budget was exceeded. A loop without a defined "done" state either over-runs (wasting CI minutes on low-value tests after a critical failure) or under-runs (stopping before meaningful coverage is achieved).
4. Feed results back make the loop cumulative, not just reactive
The highest-leverage version of a closed loop does not just react to the current failure it improves future runs based on what it learned. A self-healing event should update the element's fingerprint, not just patch the current run. A flaky test identified three times should be flagged automatically for review, not silently retried a fourth time. The loop should get smarter, not just survive.
Frequently Asked Questions
What is loop engineering?
Loop engineering is the discipline of designing AI-assisted systems around repeated cycles of action, observation, reasoning, and adjustment, rather than single-shot pipelines. The core pattern act, observe, reason, repeat originates in AI coding agent design and applies directly to QA testing, where it explains how AI testing systems investigate failures, calculate confidence, and decide whether to self-heal or escalate.
What is loop engineering in QA testing specifically?
In QA testing, loop engineering describes the structure behind modern AI testing systems: a test executes, the system observes the actual outcome, reasons about whether a failure represents a real bug or an irrelevant change, and adjusts either self-healing automatically or flagging for human review. This differs fundamentally from traditional automation, which reports pass or fail with no mechanism to interpret why.
What is the difference between open-loop and closed-loop testing?
Open-loop testing executes a script and reports a result without investigating the cause of failure a traditional Selenium test that throws an exception and stops is open-loop. Closed-loop testing observes the failure, gathers additional context, reasons about whether the underlying intent of the test is still valid, and adjusts accordingly healing automatically when confidence is high, escalating to a human when it is not.
How does self-healing test automation use loop engineering principles?
Self-healing automation is a closed feedback loop applied to element identification: it attempts to locate an element (act), evaluates multiple signals when the primary method fails (observe), calculates a confidence score for whether the element has simply changed implementation rather than disappeared (reason), and either heals the test automatically or escalates for review (adjust). Each healing event also improves the system's fingerprint of that element for future runs, making the loop cumulative.
Why does loop engineering matter for CI/CD pipelines?
CI/CD pipelines are themselves a feedback loop. Poorly engineered loops produce flaky tests that erode trust (loops that never close cleanly) or repeated failures that nobody investigates (loops with no adjustment mechanism). Applying loop engineering explicit confidence thresholds, clear termination conditions, and cumulative feedback produces pipelines that get more reliable over time instead of just generating more data for humans to manually sort through.
External references
- What Is Loop Engineering? — Kilo — Foundational definition from AI coding agent design
- What Is Loop Engineering? — MindStudio — Agent loop architecture reference
- Feedback loop engineering — Daniel Demmel — Practitioner perspective on closing the loop
- Tricentis QA Trends 2026 — AI-generated code and closed-loop QA systems
- DORA State of DevOps 2025 — CI/CD feedback loop performance data
- Capgemini World Quality Report 2025 — Test maintenance statistics
- Control theory — feedback systems — Theoretical origin of closed-loop system design
A testing platform built on closed-loop principles, not open-loop guesswork
Robonito observes, reasons, and adjusts on every test run self-healing through confidence scoring, generating tests from real usage patterns, and feeding results back to get smarter over time. Covers web, mobile, API, and desktop. Start free and see the loop close on your first broken selector. Start free at Robonito.com →
Automate your QA — no code required
Stop writing test scripts.
Start shipping with confidence.
Join thousands of QA teams using Robonito to automate testing in minutes — not months.
